Have you ever had a great image idea in mind, but AI tools can’t quite execute it exactly the way you want? Or wanted to edit a photo in a certain way, but the existing models messed up the whole picture? This is a concern familiar to many of us who deal with the world of generative AI. The good news is that Google seems to have found a powerful answer to these challenges with its latest achievement. In this article, we will take a look at AI photo editing with Google’s latest tool, the Gemini 2.5 Flash Image model, which has been causing a stir in the developer community under the codename’ nano-banana’.
Google recently unveiled this advanced model, which represents a significant leap forward not only in creating images but also in editing them accurately and intelligently. The model is so powerful that many are calling it “GPT-4’s moment for visualization models.” Let’s take a look at what it has in store and why it’s so exciting.

What is Gemini 2.5 Flash Image? A revolution in the world of imaging
The Gemini 2.5 Flash Image model is the latest addition to Google’s Gemini family, distinguishing itself with its focus on ultra-fast, precise AI-powered photo production and editing. Unlike other models, it enables real-time image manipulation with precise control. Tested on public platforms like LMArena under the nickname nano-banana, it has set new performance benchmarks and opened a notable lead over its competitors.
Unlike earlier models that often struggled with minor edits or maintaining consistency, Gemini 2.5 Flash Image allows users to make complex changes to images using simple, conversational commands. It acts as an intelligent, creative assistant, capturing your ideas with astonishing accuracy.
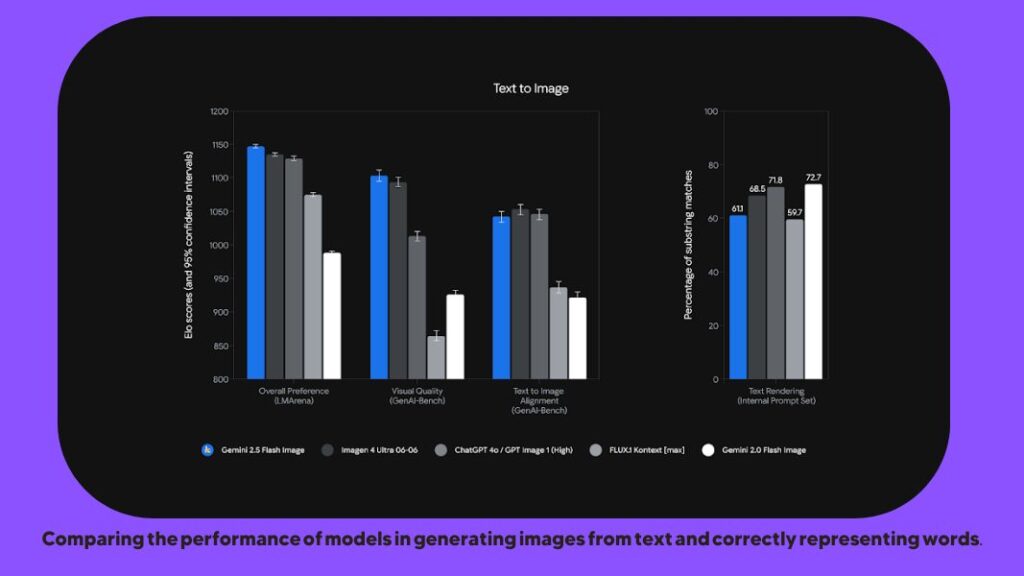
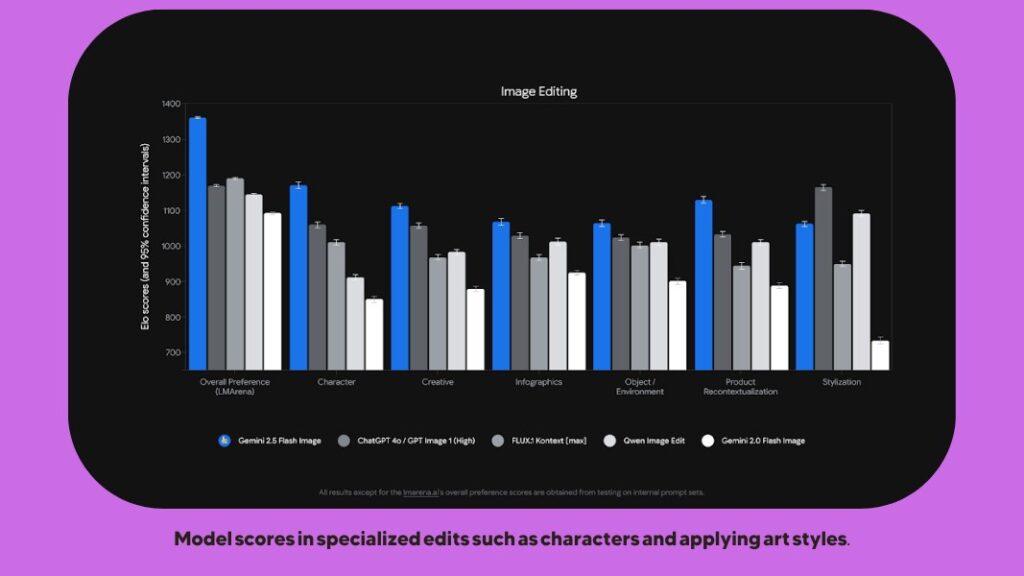
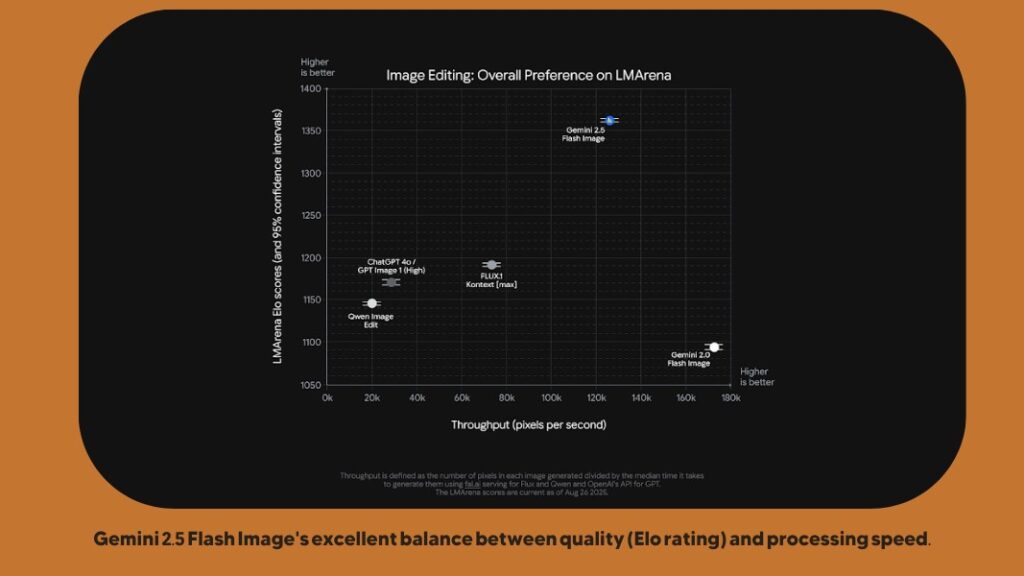
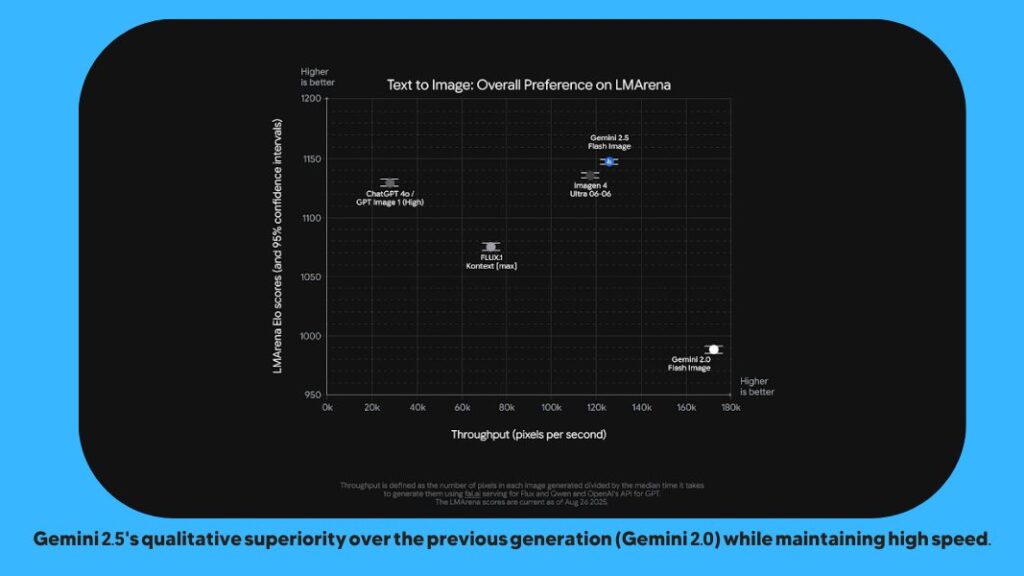
Key features that set Gemini 2.5 Flash apart
- Character Consistency: One of the biggest challenges in visual storytelling with AI is maintaining a consistent look for a character across different scenes and outfits. This model enables you to place a character in various environments, change their outfit, or even envision them at different ages without altering their core features or facial characteristics. This is incredibly useful for creating comics, storyboards, or advertising campaigns.

- Prompt-based Editing: Simply describe what you want changed. The model edits images as requested, without complex tools or unwanted changes.

- Multi-image Fusion: This feature allows you to combine up to three images to create a new work of art. You can take an object from one photo and place it in another scene, or apply the texture of one image to an object in another. This feature opens up new doors for creativity. [Suggested Image: An image that shows the result of a creative combination of two or more different photos.]

- Real-world Knowledge: The model’s understanding of logic, physics, and context helps it create more realistic images from complex prompts.
Why is this model a milestone in AI photo editing?
Limitations and challenges ahead
- Text and fine detail rendering: The model still faces challenges in accurately writing text on images or depicting very fine details, such as small faces in the distance.
- Style Transfer: Some users have reported that this model is less effective at changing the overall style of an image than other models or its previous version.
- Strict safety filters: Like many products from large companies, this model also has very strict safety filters that sometimes prevent even completely normal and safe image editing or production. This can be limiting for some applications.
However, these are challenges that the Google team is actively working on and are expected to improve in future releases.
